



知識の整理もかねて自分用に出題範囲を全て整理するつもりでしたが……。
案の定、記事が完成するより先に試験に合格してしまいました(笑)
中途半端ではありますが、えいや! で一旦アップロードします。
それでも、頻出分野(ストリームAPIなど)は整理できているので十分価値のある記事になっていると思います。
モチベーションが出てきたら残りの分野もまとめます。
いわゆる「黒本」はこちら↓
これやるだけで問題ないと思います。
本当に同じような問題が試験に出ました。
ただ、Java Silverの黒本と比べて解説で「あれ? 間違ってない?」という箇所が多かったので、別の参考書に手を出してもいいかも。まあ、何かおかしいと思ったらネットで調べましょう。
クラスとインターフェース
ネストしたクラス
「クラスの中で定義されるクラス」であり、以下の4種類があります。
- インナークラス
- staticインナークラス
- ローカルクラス
- 匿名クラス
インナークラスとstaticインナークラスは外側クラスのフィールドであり、ローカルクラスと匿名クラスはメソッド内で使用されるローカル変数です。
// 一番外側のクラス
public class Outer {
// ①インナークラス
private class Inner{}
// ②staticインナークラス
public static class StaticInner{}
public void testMethod(){
// ③ローカルクラス
class Local{}
// ④匿名クラス
Sample sample = new Sample(){};
}
}
インナークラス
- 外側クラスのフィールドとしてクラスを定義したもの
- ただのフィールドなので他のフィールドと同様に、アクセス修飾子は何でも使用可能
- インナークラス内ではstaticなメンバを定義できない。
* 外側クラスのインスタンス化のタイミングで定義されるので、staticとはタイミングが違うイメージ
staticインナークラス
- 外側クラスのstaticフィールドとしてクラスを定義したもの
- ただのフィールドなので他のフィールドと同様に、アクセス修飾子は何でも使用可能
- インナークラスと異なりstaticなメンバを定義できる。
- 外側クラスの非staticなメンバにアクセスできない。
* インスタンス化されているかわからないため
ローカルクラス
- アクセス修飾子は使用できない。
* そもそもローカル変数なのでメソッド外からはアクセスできないため - abstruct, finalで修飾は可能。
* アクセス修飾子ではないため - 外側クラスのメンバにアクセス可能。
- 同一メソッド内の他のローカル変数にもアクセス可能だが、final or 実質的にfinal である必要がある。
* ローカル変数はメソッドが終了すると消える一方、ローカルクラスは参照されていれば消えない。従って、ローカルクラスからローカル変数にアクセスする際、参照先が消えている可能性が出てくるので、そういった事態をふせぐため定数でなければならない。
匿名クラス
- アクセス修飾子は使用できない。
* そもそもローカル変数なのでメソッド外からはアクセスできないため - abstruct, finalでの修飾もできない。
* そもそも名前がないので、クラスに修飾子を設定するという概念がない - コンストラクタを定義できない。
* 名前がないため
* 初期化が必要な場合は初期化子{} を用いる。
インナークラスの生成方法
インナークラスはクラスではあるものの、ただの外側クラスのフィールドなので、インスタンスフィールドはクラスを生成してからしかアクセスできないし、staticフィールドは生成しなくてもクラス名でアクセスできる原則は同じです。
つまり、インナークラスは以下のようにインスタンスを作成します。
// インナークラス new Outer().new Inner(); // staticインナークラス new Outer.StaticInner();
個人的な感覚としては、インナークラスのインスタンス化は「new (new Outer()).Innner();」みたいな感じのほうがしっくりくるが、staticインナークラスの生成と滅茶苦茶見分けがつきにくくなるので致し方ないか?
インターフェース
staticメソッド
- インターフェースにもstaticメソッドを定義できる。(Java SE8~)
- staticメソッドを使用する際は、[インターフェース名].methodName() というようにstaticメソッドが定義されたインターフェース名が必要である。
つまり、インターフェースを実現したクラスであっても、[実現クラス].methodName() といった形で呼び出すことはできない。 - staticメソッドはオーバーライドできない。(インターフェース以外でも)
↑オーバーライドはインスタンスの挙動を再定義するものだが、staticメソッドはインスタンスに紐づいていなため。
やはり個人的には、「staticメソッドは(ユーティリティ的な)関数」といった考え方がしっくりきますね。
staticメソッドを定義したインターフェース名からしか呼び出しができない理由はいつくかあると思いますが、「インターフェースは多重実現できるため、名前衝突が起こりうる」というのが試験的にも明瞭で覚えやすいかなと思います。
デフォルトメソッド
- 必ずpublicとして扱われる(インターフェース内の抽象メソッドと同じ)。
- @Overrideしたメソッド内で親のデフォルトメソッドを呼び出す際は、A.super.test() といったように、[インターフェース名].super.methodName() と記述する。
* 多重実現できることを考えると、インターフェース名を指定することは自然 - @Override したメソッド内で親のデフォルトメソッドを呼び出す場合、直接実現or継承しているインターフェースのメソッドしか呼び出せない。
- インターフェースとスーパークラスに同一のシグネチャのメソッドがある場合、スーパークラスのメソッドが優先的に呼び出される。
* インターフェースのデフォルトメソッドは、あくまで他に選択肢がない場合(=デフォルト)に使用されるものであり、基本的に実装はクラスが提供すべきという思想 - インターフェースとスーパークラスに同一のシグネチャのメソッドがある場合、スーパークラスのメソッドはpublicでなければならない。
* 厳密にはインターフェースのデフォルトメソッドより緩いアクセス修飾子でなければならない。インターフェースのデフォルトメソッドはpublicなので必然的にpublic。
詳しい説明は後述
【補足】スーパークラスのメソッドがpublicでないといけないのはなぜ?
クラスCがインターフェースAを実現し、クラスBを継承しており、AとBに同一シグネチャのメソッド(test()とする)がある場合を考えます。
AのメソッドはpublicでBのメソッドはprotectedです。
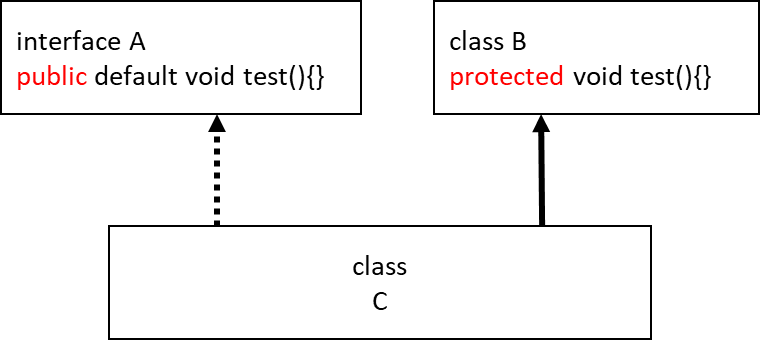
同一シグネチャのメソッドがある場合、スーパークラスのメソッドが優先されるので、testメソッドはclass Bのものが使用されます。
その場合、クラスCのtestメソッドはprotectedになります。
しかし、Javaはサブクラスはスーパークラスに置き換え可能でなければならないので、クラスCをAとして置き換えることを考えると、アクセス修飾子はAより狭くできません。
従って、必然的にBの同一シグネチャのメソッドはpublicでないとコンパイルエラーが生じます。
privateメソッド
- インターフェースにもprivateメソッドを定義できる(staticも可能)。(Java SE9~)
- 抽象メソッド、デフォルトメソッドはprivate不可。
* どちらも実現されることを前提としており、publicと解釈されるため妥当。
インターフェースのprivateメソッドは、インターフェース内で記述する処理(=デフォルトメソッドの処理)を簡略化するために使用します。
単純に何度も同じ処理を書くのは面倒なので記述を1つにまとめられるように、ということでしょう。
Enum
Enumは人間にとって分かりやすい定数を定義するためのクラスです。
定数とはいうものの1とか2とかという値というよりは、一意に識別するためのID(列挙子)を定義するという方が実際の使用イメージと近いと思います。
Enumの主なメソッド
① values()
そのEnumに定義されているすべての列挙子を配列に入れて戻すメソッド。
引数は定義されていないので、特定のインデックスのEnumのみ取り出す場合は、以下のように返り値に対してインデックスを指定すればよい。
SampleEnum.values()[1]
② valueOf()
列挙子の名前(String)から列挙子のインスタンスを取得するメソッド。
SampleEnum.values("A")
Enumのインスタンスの生成
Enumが一意に識別するための列挙子をどのように実現しているかというと、定義したEnumクラスが使用されるときに一度だけ列挙子のインスタンスを生成することで実現しています。
つまりEnumで扱う定数的なものは、そのクラスの唯一のインスタンスたちです。
Enumのコンストラクタ
前述のとおり、Enumはインスタンスを生成しているので他のクラス同様コンストラクタを定義することで処理を追加できます。
たとえば次のコードは、コンストラクタで受け取った値(“a”,”b”,”c”)をそれぞれのインスタンスのvalueにセットしています。
public enum Sampe {
A("a"), B("b"), C("c"):
private String value;
private Sample(String value){
this.value = value;
}
}
注意すべき点は、Enumのコンストラクタはprivateである必要があり省略時は暗黙的にprivateとして扱われる点です。
Enumの性質上、唯一のインスタンスを保証するためには、プログラマーが自由にインスタンスを生成できないようにする必要があるためだと思います。
関数型インターフェースとラムダ式
ほとんどJava Silverの内容なのでさくっとポイントを覚えればいいかと思います。
いろいろな省略
- パラメータの型:
- ラムダ式のパラメータで型を省略できます。型はコンテキストから推論されます。
- 例:(String s) -> s.length() は (s) -> s.length() と書けます。
- 括弧(単一のパラメータの場合):
- 単一のパラメータの場合、パラメータを囲む括弧を省略できます。
- 例:(s) -> s.isEmpty() は s -> s.isEmpty() と書けます。
- 波括弧とreturn文(単一の式の場合):
- ラムダ本体が単一の式の場合、波括弧と return 文を省略できます。
- 例:(a, b) -> { return a + b; } は (a, b) -> a + b と書けます。
java.lang.functionの代表的なクラス
| インターフェース | メソッド | 戻り値型 | |
|---|---|---|---|
| Supplier<T> | get() | T | 何も受け取らず、結果を供給します。 |
| Consumer<T> | accept(T t) | void | 単一の入力引数を受け取り、結果を返しません。 |
| Function<T,R> | apply(T t) | R | 単一の入力引数を受け取り、結果を返します。 |
| Predicate<T> | test(T t) | boolean | 単一の入力引数を受け取り、ブール値(真偽値)を返します。 |
| UnaryOperator<T> | apply(T t) | T | 単一の入力引数を受け取り、同じ型の結果を返します。 |
BiConsumerなど「Bi」がつくと、受け取る引数が2つになります。
UnaryOperatorのBi系であるBinaryOperatorは、同じように引数が2つになりますがジェネリクスの型パラメータは1つだけで増えません。
つまり、BinaryOperatorは受け取る2つの型も返す型もすべて同一です。
以下、試験でしか使わない世界一無駄な5分で考えた語呂合わせ。
ファンタ(Function)のアップル(apply)
さあ(Supplier)、ゲット。(get)
今度の(Consumer)のアクション(accept)
プチ(Predicate)テスト(test)
細かな知識
Predicateの合成
Predicateはインスタンスを組み合わせることで、「and」や「or」の条件を表現することができます。
Predicate p1 = str -> str.startWith("p");
Predicate p2 = str -> str.startWith("s");
// falseを返す
p1.and(p2).test("path");
// trueを返す
p1.or(p2).test("path");
Predicateは関数型インターフェースなので抽象メソッドは1つのはずですが、andやorはdefaultメソッドとして定義されているので問題ありません。
Functionの合成
Functionはインスタンスを組み合わせることで処理の連結ができます。
次のメソッドを使用します。
- andThen:順次処理
a.anthThen(b);
a→bの順で処理 - compose:逆順処理
a.compose(b)
b→aの順で処理
Function f = str -> str + "f";
Function g = str -> str + "g";
// "fg"を返す
System.out.println(f.andThen(g).apply(""));
// "gf"を返す
System.out.println(f.compose(g).apply(""));
ちなみに「compose」は数学における合成の文脈で使用される単語です。
f(g(5)) みたいなやつですね。懐かしい……。
google検索すると「作曲」がトップに出て首を傾げたので、ちょっとした補足でした。
並列処理
並列処理(並行処理)は、複数の処理を同時に実行することです。
時間のかかる処理を実行したり、どのくらい時間がかかるかわからない処理(外部のAPI実行など)をしたりする際に、別の処理を進めることでパフォーマンスを向上させることができます。
実務上、並行処理と並列処理を区別する機会はあまりない気がしますが、簡単には以下のようなイメージです。
- 並行処理
1人の人が複数の作業机を並べて、順繰り別々の処理をする。 - 並列処理
複数の人が、それぞれ別々の処理をする。
本章では、Javaで並行処理を実現する手段を整理していきます。
Threadクラス
Threadクラスに実行する処理を記述して、start()メソッドで別スレッドを生成し処理を実行する方法です。
実行する処理の記述方法には次の2種類があります。
Threadのrun()メソッドをoverride
// 実行する処理の記述
Thread t = new Thread(){
@Override
public void run(){
System.out.println("sub thread!!");
}
};
// スレッドの生成&処理の実行
t.start();
ThreadのコンストラクタにRunnableの実現クラスを渡す
// 実行する処理の記述
Thread t = new Thread(new Runnable(){
@Override
public void run(){
System.out.println("sub thread!!");
}
});
// スレッドの生成&処理の実行
t.start();
Ruunableインターフェースは関数型インターフェースでもあるので、ラムダ式を利用して少しだけすっきりと記述できます。
// ラムダ式を使用した例
// 実行する処理の記述
Thread t = new Thread(()->{
System.out.println("sub thread!!");
}
);
// スレッドの生成&処理の実行
t.start();
注意点
Threadの処理はrunメソッドに記述しますが、実行はstartメソッドで行わないと別スレッドが生成されません。
次の例では、runメソッドを直接使用した場合はmainスレッドで処理が実行され、startメソッドから使用された場合はsubスレッド(Thread-0)で実行されていることが確認できます。
※Thread.currentThread().getName() は現在のスレッド名を取得するメソッドです。
// 実行する処理の記述
Thread t = new Thread(){
@Override
public synchronized void start(){
System.out.println("start : " + Thread.currentThread().getName());
super.start();
}
@Override
public void run(){
System.out.println("run : " + Thread.currentThread().getName());
}
};
// スレッドの生成&処理の実行
t.run();
// 出力結果↓
// run : main
t.start();
// 出力結果↓
// start : main
// run : Thread-0
Executorフレームワークの利用
なぜ使用するか
- スレッド生成は重い処理なので、できるだけスレッドを生成しないほうがパフォーマンスが上がる。
- あらかじめいくつかスレッドを生成しておき、処理が終わったスレッドを使いまわせば生成を抑えられる。
- スレッドの使いまわしを管理できるインターフェースを使おう!
つまり、スレッドを大量に使用する必要がある場合のパフォーマンス向上が目的です。
スレッドをあらかじめ生成し使いまわす処理を実現するのが、JavaのExcecutorインターフェースを親とする一連のインターフェースたちです。
あらかじめスレッドを生成してそのスレッドを利用する仕組みをスレッドプールといいます。
Executorフレームワークの構成
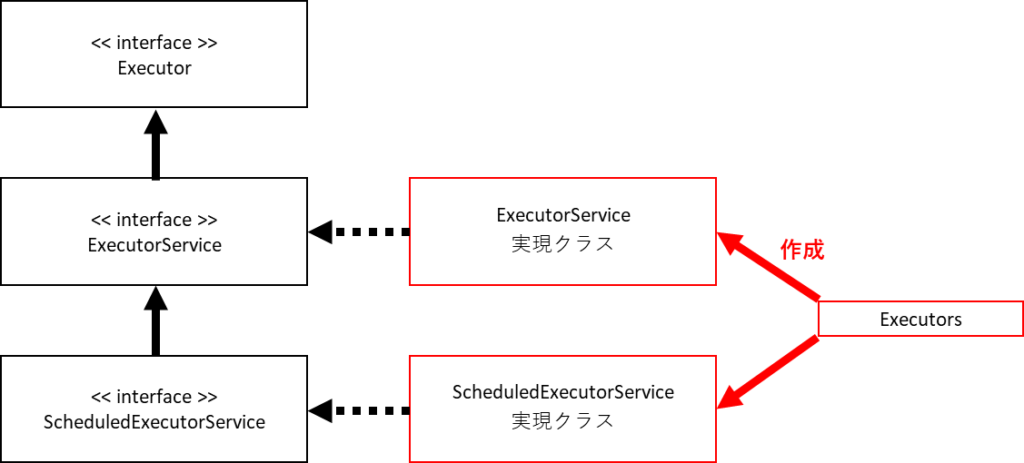
Executorインターフェースを継承する次の2つのインターフェースを利用して、スレッドの管理を行います。
- ExecutorService
- ScheduledExcecutorService
これらのインターフェースはファクトリクラス(?)であるExcecutorsのメソッドを使用して生成することができます。
もちろん独自の定義でExecutorインターフェースの実現インスタンスを生成することも可能ですが、Excecutorsのメソッドで事足りるならそれがわかりやすそうです。
ExecutorServiceを作成するメソッド
作成したインスタンスのsubmitメソッドに処理を記述したRunnableを渡すことで、別スレッドで処理を実行できます。
newSingleThreadExecutor
1つだけスレッドを生成しプールすることができます。
次のコード例を実行すると、同じ1つのスレッドが使いまわされていることがわかります。
ExecutorService exec = Executors.newSingleThreadExecutor();
for(int i=0;i<3;i++){
exec.submit(new Runnable(){
@Override
public void run(){
System.out.println("run : " + Thread.currentThread().getName());
}
});
}
// 出力
// run : pool-1-thread-1
// run : pool-1-thread-1
// run : pool-1-thread-1
newFixedThreadPool
決まった数のスレッドを生成しプールすることができます。
次のコード例を実行すると、最初に生成した3種類のスレッドのみが使用されていることがわかります。
ExecutorService exec = Executors.newFixedThreadPool(3);
for(int i=0;i<5;i++){
exec.submit(new Runnable(){
@Override
public void run(){
System.out.println("run : " + Thread.currentThread().getName());
}
});
}
// 出力
// run : pool-1-thread-1
// run : pool-1-thread-2
// run : pool-1-thread-3
// run : pool-1-thread-3
// run : pool-1-thread-3
newCachedThreadPool
必要に応じてスレッドを生成し、生成したスレッドが60秒間使用されなければ破棄されるスレッドプールを作成します。
- どのくらいスレッド数(=並行処理)が必要かわからない
- けど、できるだけ無駄にスレッドは生成したくない
という場合に有用です。
次のコード例を実行すると、60秒より長い時間が経過するとスレッドが破棄され、別のスレッドが作成されていることがわかります。
ExecutorService exec = Executors.newCachedThreadPool();
Runnable runPrint = ()->{
System.out.println("run : " + Thread.currentThread().getName());
};
System.out.println("*****First Run*****");
for(int i=0;i<5;i++){
exec.submit(runPrint);
}
Thread.sleep(1000*65);
System.out.println("*****Run after 65sec*****");
for(int i=0;i<5;i++){
exec.submit(runPrint);
}
// 出力例
// *****First Run*****
// run : pool-1-thread-1
// run : pool-1-thread-2
// run : pool-1-thread-3
// run : pool-1-thread-4
// run : pool-1-thread-2 ←thread-2が使いまわされている
// *****Run after 65sec*****
// run : pool-1-thread-5 ←First Runで使用されていたthread-1~4は使われていない
// run : pool-1-thread-5
// run : pool-1-thread-6
// run : pool-1-thread-6
// run : pool-1-thread-7
ScheduledExecutorServiceのメソッド
ScheduledExecutorServiceはExecutorServiceを拡張したインターフェースで、処理を遅延させて実行したり定期的に実行したりできます。
いくつかのメソッドが用意されており、柔軟に実行タイミングを制御することができます。
schedule
別スレッドで処理を遅延実行します。
次の引数を渡します。
- 実行したい処理(Runnable)
- 遅延させる時間(long)
- 遅延させる時間の単位(java.util.concurrent.TimeUnit)
ScheduledExecutorService exec = Executors.newSingleThreadScheduledExecutor();
exec.schedule(()->{
System.out.println("Run!!");
exec.shutdown();
}, 1, TimeUnit.SECONDS);
Thread.sleep(500);
System.out.println("Main Thread");
// 出力
// Main Thread ←こちらが先に出力されていることに注目!!
// Run!!
scheduleAtFixedRate
別スレッドで処理を定期的に実行します。
実行頻度(Rate)が固定(Fixed)なので、実行開始から次の実行開始までの最小時間を指定します。
次の引数を渡します。
- 実行したい処理(Runnable)
- 初期遅延の時間(long)
- インターバルの時間(long)
- 時間の単位(java.util.concurrent.TimeUnit)
ScheduledExecutorService exec = Executors.newSingleThreadScheduledExecutor();
exec.scheduleAtFixedRate(()->{
System.out.println("Run At Fixed Rate!!");
},300, 200, TimeUnit.MILLISECONDS);
for(int i=0;i<5;i++){
Thread.sleep(200);
System.out.println("Main Thread:" + (i+1));
};
exec.shutdown();
// 出力例
// shutdownが呼ばれるまで定期的に処理が呼ばれていることに注目!!
// Main Thread:1
// Run At Fixed Rate!!
// Main Thread:2
// Run At Fixed Rate!!
// Main Thread:3
// Run At Fixed Rate!!
// Main Thread:4
// Run At Fixed Rate!!
// Main Thread:5
scheduleWithFixedDelay
別スレッドで処理を定期的に実行します。
遅延時間(Delay)が固定(Fixed)なので、実行終了から次の実行開始までの最小時間を指定します。
次の引数を渡します。
- 実行したい処理(Runnable)
- 初期遅延の時間(long)
- 遅延の時間(long)
- 時間の単位(java.util.concurrent.TimeUnit)
基本的に「scheduleAtFixedRate」と同じですが、
- AtFixedRate: 処理のStart – Start 間のインターバルを指定
- WithFixedDelay: 処理のEnd – Start 間のインターバルを指定
という違いがあります。
RateがStart – StartでRSSですね。
時間がかかる処理の場合、AtFixedRateだとすぐに次の処理が実行される可能性があり、システムに負荷をかける可能性があるので注意が必要です。
ScheduledExecutorService execRate = Executors.newSingleThreadScheduledExecutor();
ScheduledExecutorService execDelay = Executors.newSingleThreadScheduledExecutor();
// scheduleAtFixedRate
execRate.scheduleAtFixedRate(()->{
try{
Thread.sleep(200);
System.out.println(" Run At Fixed Rate!!");
}catch(Exception e){}
},100, 200, TimeUnit.MILLISECONDS);
// scheduleWithFixedDelay
execDelay.scheduleWithFixedDelay(()->{
try{
Thread.sleep(200);
System.out.println(" Run With Fixed Delay!!");
}catch(Exception e){}
},100, 200, TimeUnit.MILLISECONDS);
for(int i=0;i<5;i++){
Thread.sleep(200);
System.out.println("Main Thread:" + (i+1));
};
execRate.shutdown();
execDelay.shutdown();
// 出力例
// Main Thread:1
// Run With Fixed Delay!! ←初期遅延は同じなので、RateもDelayもほぼ同時に実行されます。
// Run At Fixed Rate!!
// Main Thread:2
// Run At Fixed Rate!! ←Rateは200ms経過して処理が終わっていたらすぐ次の処理を実行しています。
// Main Thread:3
// Run With Fixed Delay!! ←Delayは処理が終わったあと200ms待っているので、後ろ倒しされています。
// Run At Fixed Rate!!
// Main Thread:4
// Run At Fixed Rate!!
// Main Thread:5
// Run With Fixed Delay!!
// Run At Fixed Rate!!
さて、上の例ではExecutors.newSingleThreadScheduledExecutor()を2回使用してScheduledExecutorServiceの実現インスタンスを2つ生成しましたが、ScheduledExecutorServiceでもThread Poolを利用してあらかじめ複数のスレッドを生成しておき、そのスレッドを利用することができます。
Thread Poolを生成するメソッドが、Executors.newScheduledThreadPoolです。
ScheduledExecutorService exec = Executors.newScheduledThreadPool(2);
// scheduleAtFixedRate
exec.scheduleAtFixedRate(()->{
try{
Thread.sleep(200);
System.out.println(" Run At Fixed Rate!!");
}catch(Exception e){}
},100, 200, TimeUnit.MILLISECONDS);
// scheduleWithFixedDelay
exec.scheduleWithFixedDelay(()->{
try{
Thread.sleep(200);
System.out.println(" Run With Fixed Delay!!");
}catch(Exception e){}
},100, 200, TimeUnit.MILLISECONDS);
for(int i=0;i<5;i++){
Thread.sleep(200);
System.out.println("Main Thread:" + (i+1));
};
exec.shutdown();
Futureインターフェース
別スレッドの処理の結果を確認したり、スレッドを止めたりするためのインターフェースです。
まだ処理が終わっていないけど、「後で」処理結果が終わるよ、という意味でFutureなんだと思います。
Futureオブジェクトはこれまで確認してきたExecutorServiceのsubmitメソッドの戻り値で取得できます。
余談ですがJavaのFutureはJavaScriptでいうとPromiseに相当すると思います。
将来の「約束」……、おしゃれですね(?)
別スレッドが終わるのを待機
get()メソッドを使用することで、別スレッドの処理が終了するまで待機することができます。
get()の名の通り、主目的は別スレッドの処理の結果を受け取ることですが、副次的な使い方として処理の待ち合わせができることは知識の片隅にあると良いかもです。
ちなみに、Runnableクラスは実行処理しか記述できず値を返すことができないので、get()の戻り値はnullになります。
ExecutorService exec = Executors.newSingleThreadExecutor();
Future future = exec.submit(()->{
try{
Thread.sleep(1000);
System.out.println("Submit!!");
}catch(Exception e){}
});
System.out.println(future.get());
// 出力. 別スレッドの処理は1secかかるが、Finish!! のあとにnullが出力されている.
// Submit!!
// null
別スレッド終了時に固定値を受け取る
前述のとおりRunnableは戻り値を返すことができませんが、ExecutorServiceのsubmitの第二引数に指定した値をFutureオブジェクトのget()メソッドで取得することができます。
この場合、Futureの型パラメータ(=将来何の型が返るか)とsubmitで指定する戻り値の型は一致する必要があります。
次の例のように、Future<String>とsubmitの第二引数の型(今回はString)が一致する必要があります。
ExecutorService exec = Executors.newSingleThreadExecutor();
Future<String> future = exec.submit(()->{
try{
Thread.sleep(1000);
System.out.println("Submit!!");
}catch(Exception e){}
},"Finish!!");
System.out.println(future.get());
// 出力
// Submit!!
// Finish!!
ただ、実は型推論が働くようなのでFutureのジェネリクスを指定しなくてもsubmitの第二引数の型だと推論してくれます。
つまり、先のコード2行目で
Future future = exec.submit(()->{
とジェネリクスを省略しても問題なく動きます。
別スレッド終了時に任意の値を受け取る(Callable)
Runnbalbeクラスは戻り値を返すことができませんが、Callableクラスを使用することで別スレッドの処理の結果を返すことができます。
戻り値の型はCallableのジェネリクスで指定します。
ExecutorService exec = Executors.newSingleThreadExecutor();
Future future = exec.submit(new Callable<String>(){
@Override
public String call(){
// 日本時間の現在時刻を取得
LocalTime now = LocalTime.now();
// フォーマットを指定
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("HH:mm");
// フォーマット済みの時刻を文字列として取得
return now.format(formatter);
}
});
System.out.println(future.get());
// 出力
// 00:42 (現在時刻)
CallableはRunnable同様関数型インターフェースなので、ラムダ式で簡略表現できます。
Runnableと見分けがつきにくいですが、戻り値を戻す=returnで何かを返していればCallableです。
その場合、returnする型から戻り値の型が推論されます。
次のコードはラムダ式の例です。
ExecutorService exec = Executors.newSingleThreadExecutor();
Future future = exec.submit(()->{
// 日本時間の現在時刻を取得
LocalTime now = LocalTime.now();
// フォーマットを指定
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("HH:mm");
// フォーマット済みの時刻を文字列として取得
return now.format(formatter);
});
System.out.println(future.get());
// 出力
// 00:42 (現在時刻)
別スレッドで発生した例外を受け取る
実行中の別スレッドで例外が発生した場合、すぐにメインスレッドで例外がスローされるのではなくFutureのgetメソッド使用時に例外がスローされます。
Futureのgetメソッドがスローするのは別スレッド内で発生した例外クラスではなくExecutionExceptionクラスの例外です。
catchする際は注意です。
(まあ、エディタが教えてくれる十思いますが)
別スレッドで発生した例外の中身はExecutionException内部に保持されているため、発生した例外の確認は可能です。
ExecutorService exec = Executors.newSingleThreadExecutor();
Future<String> future = exec.submit(()->{
throw new Exception("Sample Exception");
});
try{
future.get();
}catch(ExecutionException e){
System.out.println(e.toString());
}
// 出力
// 発生しているのはExecutionException
// 例外のメッセージはSample Exception になっている
// java.util.concurrent.ExecutionException: java.lang.Exception: Sample Exception
複数の非同期処理の制御
複数スレッドの終了を待つ(CyclicBarrier)
複数スレッドの同期化処理はCyclicBarrierクラスで実現できます。
同期化とは待ち合わせみたいなものです。
スレッドはそれぞれが自由に処理をするので、処理が終了するタイミングがまちまちです。
そこで、処理が終わった=待ち合わせ場所についたことをそれぞれのスレッドが知らせてあげることで、全員が終了したタイミングでアクションを起こせます。
- 待ち合わせのポイントのことをバリアー
- 待ち合わせたあとに実行する処理のことをバリアーアクション
と言います。
CyclicBarrierクラスは、一度アクションを起こした後も使いまわせるのでCyclic(循環)という名前がついているらしいです。
CyclicBarrierクラスのコンストラクタには次の引数があります。
- int parties: 待ち合わせる人数です。
- Runnable barrierAction: 人数が集まった後に実行するアクションです。
次のコード例を見ると以下のようなことが確認できます。
- CyclicBarrierのawait()を呼び出したタイミングで処理が一時停止している。
- 6つのスレッドのうち最初3つがawaitに達した段階でバリアーアクションが実行されている。
- 一度バリアーアクションが実行された後、再び3つのスレッドがawaitに達すると再度バリアーアクションが実行されている。
// バリアーを作成
CyclicBarrier barrier = new CyclicBarrier(3,()->{
System.out.println("Barrier Action !!");
});
ExecutorService exec = Executors.newFixedThreadPool(5);
for(int i=0;i<5;i++){
Thread.sleep(200);
exec.submit(()->{
System.out.println("run : " + Thread.currentThread().getName());
try{
// バリアーで待ち合わせ
barrier.await();
}catch(InterruptedException|BrokenBarrierException e){}
System.out.println("finish : " + Thread.currentThread().getName());
});
}
// 出力
// run : pool-1-thread-1
// run : pool-1-thread-2
// run : pool-1-thread-3
// Barrier Action !!
// finish : pool-1-thread-3
// finish : pool-1-thread-1
// finish : pool-1-thread-2
// run : pool-1-thread-4
// run : pool-1-thread-5
// run : pool-1-thread-6
// Barrier Action !!
// finish : pool-1-thread-6
// finish : pool-1-thread-4
// finish : pool-1-thread-5
処理の排他制御(synchronized)
複数スレッドで処理を行う場合、別々のスレッドから同時に同じインスタンスにアクセスすることで想定外の挙動を示すことがあります。
次のコードでは、submitによりrunメソッドが呼び出されるたびに、numフィールドの値が1増えることが予想されますが、実際の出力を見ると値が変化していません。
これは、numフィールドが更新される前に別スレッドがnumフィールドにアクセスしているためです。
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main implements Runnable{
private int num = 0;
public static void main(String[] args) throws Exception {
Main main = new Main();
ExecutorService exec = Executors.newFixedThreadPool(5);
for(int i=0;i<5;i++){
Thread.sleep(100);
exec.submit(main);
}
}
@Override
public void run(){
try{
int currentNum = this.num;
System.out.println("currentNum=" + currentNum + " : " + Thread.currentThread().getName());
Thread.sleep(1000);
// ここでカウントアップ!!
this.num = currentNum + 1;
}catch(InterruptedException e){}
}
}
// 出力 値が全部0!!
// currentNum=0 : pool-1-thread-1
// currentNum=0: pool-1-thread-2
// currentNum=0: pool-1-thread-3
// currentNum=0: pool-1-thread-4
// currentNum=0: pool-1-thread-5
synchronizedメソッド
カウントアップされてから、つぎのメソッドが実行されるようにするために、runメソッドにsynchronizedキーワードを使用します。
synchronizedをメソッドにつけることで、同一インスタンスでそのメソッドが同時に実行されないように制御することができます。
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main implements Runnable{
private int num = 0;
public static void main(String[] args) throws Exception {
Main main = new Main();
ExecutorService exec = Executors.newFixedThreadPool(5);
for(int i=0;i<5;i++){
Thread.sleep(100);
exec.submit(main);
}
}
@Override
public synchronized void run(){
try{
int currentNum = this.num;
System.out.println("currentNum=" + currentNum + " : " + Thread.currentThread().getName());
Thread.sleep(100);
// ここでカウントアップ!!
this.num = currentNum + 1;
}catch(InterruptedException e){}
}
}
// 出力 カウントアップされている!!
// currentNum=0: pool-1-thread-1
// currentNum=1: pool-1-thread-2
// currentNum=2: pool-1-thread-3
// currentNum=3: pool-1-thread-4
// currentNum=4: pool-1-thread-5
synchronizedブロック
synchronizedをメソッド内の部分的な処理に適応したい場合は、synchronizedブロックを使用します。
synchronized(インスタンス){処理} という形で表現され、処理を実行できるのは()の中に与えられたインスタンスにつき1スレッドだけです。
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main implements Runnable{
private int num = 0;
public static void main(String[] args) throws Exception {
Main main = new Main();
ExecutorService exec = Executors.newFixedThreadPool(5);
for(int i=0;i<5;i++){
Thread.sleep(10);
exec.submit(main);
}
}
@Override
public void run(){
try{
System.out.println("Start!!" + " : " + Thread.currentThread().getName());
synchronized(this){
int currentNum = this.num;
Thread.sleep(100);
System.out.println("currentNum=" + currentNum + " : " + Thread.currentThread().getName());
// ここでカウントアップ!!
this.num = currentNum + 1;
}
}catch(InterruptedException e){}
}
}
// 出力
// 処理自体は並行してStartしているが、
// synchronized(this){}に囲まれた部分は順番に実行されている。
// → currentNumがカウントアップしている。
// Start!! : pool-1-thread-1
// Start!! : pool-1-thread-2
// Start!! : pool-1-thread-3
// Start!! : pool-1-thread-4
// Start!! : pool-1-thread-5
// currentNum=0 : pool-1-thread-1
// currentNum=1 : pool-1-thread-5
// currentNum=2 : pool-1-thread-4
// currentNum=3 : pool-1-thread-3
// currentNum=4 : pool-1-thread-2
逆に言えばsynchronized(インスタンス){処理}で()の中のインスタンスが異なれば、並行して処理が実行されます。
次の例は、先ほどのコードとは違いスレッドごとに別のインスタンスをsynchronizedブロックに与えているため、ブロック内部も並行して処理が実行されています。
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main implements Runnable{
private int num = 0;
private static Object[] mLocks = new Object[5];
private static int mIndex = 0;
public Main(){
for(int i=0;i<mLocks.length;i++){
mLocks[i] = new Object();
}
}
public static void main(String[] args) throws Exception {
Main main = new Main();
ExecutorService exec = Executors.newFixedThreadPool(5);
for(int i=0;i<5;i++){
Thread.sleep(10);
exec.submit(main);
mIndex += 1;
}
}
@Override
public void run(){
try{
System.out.println("Start!!" + " : " + Thread.currentThread().getName());
synchronized(mLocks[mIndex]){
int currentNum = this.num;
Thread.sleep(100);
System.out.println("currentNum=" + currentNum + " : " + Thread.currentThread().getName());
// ここでカウントアップ!!
this.num = currentNum + 1;
}
}catch(InterruptedException e){}
}
}
// 出力
// 処理自体は並行してStartしているが、
// synchronized(this){}に囲まれた部分も並行して処理されている
// → currentNumが全て等しい
// Start!! : pool-1-thread-1
// Start!! : pool-1-thread-2
// Start!! : pool-1-thread-3
// Start!! : pool-1-thread-4
// Start!! : pool-1-thread-5
// currentNum=0 : pool-1-thread-3
// currentNum=0 : pool-1-thread-2
// currentNum=0 : pool-1-thread-1
// currentNum=0 : pool-1-thread-4
// currentNum=0 : pool-1-thread-5
デッドロック・ライブロック
排他制御を行うためにインスタンスのロックを複数スレッドで取得しようとすることでで処理がとまることがあります。
プロセスが止まるのが「デッド」ロックで、プロセスは動くんだけど処理が進まないのが「ライブ」ロックです。
デッドロック
デッドロックは、スレッドA、Bが互いの相手が保持しているインスタンスのロックを開放するのを待った結果処理がストップしている状態です。
例えば、狭い廊下でA君とB君が向かい合って立ち止まり、「君が先に行ってよ」とお互いに言い合っている状況です。A君はB君が動くのを待っていて、B君はA君が動くのを待っているので、どちらも進むことができません。
ライブロック
ライブロックは、スレッドA、Bが互いに相手が必要とするリソースを譲ろうとすることで、同じ動きを繰り返して処理がストップしている状態です。
例えば、A君とB君が狭い廊下で向かい合い、「じゃあ、僕が右に行くね」と言って両方とも右に動くけれど、またぶつかってしまい、「あ、じゃあ左に行くね」と両方とも左に動く。これを何度も繰り返して、結局どちらも進めない状態です。
/*
* デッドロックのコード例
*/
final Object lock1 = new Object();
final Object lock2 = new Object();
Thread thread1 = new Thread(() -> {
synchronized (lock1) {
System.out.println("Thread 1: Holding lock 1...");
try { Thread.sleep(100); } catch (InterruptedException e) {}
System.out.println("Thread 1: Waiting for lock 2...");
synchronized (lock2) {
System.out.println("Thread 1: Holding lock 1 & 2...");
}
}
});
Thread thread2 = new Thread(() -> {
synchronized (lock2) {
System.out.println("Thread 2: Holding lock 2...");
try { Thread.sleep(100); } catch (InterruptedException e) {}
System.out.println("Thread 2: Waiting for lock 1...");
synchronized (lock1) {
System.out.println("Thread 2: Holding lock 2 & 1...");
}
}
});
thread1.start();
thread2.start();
// 出力 thread1,2ともに必要なlockを獲得できないので処理が止まっています。
// Thread 1: Holding lock 1...
// Thread 2: Holding lock 2...
// Thread 1: Waiting for lock 2...
// Thread 2: Waiting for lock 1...
一応ロックする順番をそろえる(先のコード例ではどちらもlock1→lock2の順でロックする)ことでデッドロックを抑制することができます。
ただ、個人的にはそんな危ないコードは書かない方がいい気がします。
フィールドの排他制御(Atomic)
単一のフィールドの排他制御を実現する場合はjava.util.concurrent.atomicパッケージのクラスを使うとシンプルに表現できることがあります。
次の例ではフィールドを「取得」して「更新」が終わらないうちに別のスレッドが値を「取得」してしまったために、フィールドが想定外の値になっています。
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main {
public static class Counter {
private int num = 0;
public void addNum(int addNum) {
// 値の取得
System.out.println(Thread.currentThread().getName() + " : Get");
int current_num = this.num;
try{
Thread.sleep(50);
}catch(InterruptedException e){}
// 値の更新
System.out.println(Thread.currentThread().getName() + " : Update");
this.num = current_num + addNum;
}
public int getNum() {
return this.num;
}
}
public static void main(String[] args) throws Exception {
Counter counter = new Counter();
ExecutorService exec = Executors.newFixedThreadPool(3);
for(int i=0;i<3;i++){
exec.submit(()->{
counter.addNum(1);
});
Thread.sleep(10);
}
Thread.sleep(300);
System.out.println(counter.getNum());
}
}
// 出力. addNumが3回呼ばれているが1しか値が増えていない.
// pool-1-thread-1 : Get
// pool-1-thread-2 : Get
// pool-1-thread-3 : Get
// pool-1-thread-1 : Update
// pool-1-thread-2 : Update
// pool-1-thread-3 : Update
// 1
次のようにAtomicValueクラスを使用すると、値の取得と更新の間に他のスレッドの処理が割り込まないようになります。
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
public class Main {
public static class Counter {
private AtomicInteger num = new AtomicInteger(0);
public void addNum(int addNum) {
// 値の取得と更新
System.out.println(Thread.currentThread().getName() + " : Get & Update");
this.num.addAndGet(addNum);
}
public int getNum() {
return this.num.intValue();
}
}
public static void main(String[] args) throws Exception {
Counter counter = new Counter();
ExecutorService exec = Executors.newFixedThreadPool(3);
for(int i=0;i<3;i++){
exec.submit(()->{
counter.addNum(1);
});
}
Thread.sleep(300);
System.out.println(counter.getNum());
}
}
// 出力. addNumが3回呼ばれて+3されている.
// pool-1-thread-3 : Get & Update
// pool-1-thread-1 : Get & Update
// pool-1-thread-2 : Get & Update
// 3
スレッドセーフなクラス
スレッドセーフなクラスは、複数のスレッドから同時にアクセスされても、データの整合性が保たれるように設計されたクラスです。
さきほどのAtomicIntegerもスレッドセーフなクラスと言えます。
具体的には、以下の条件を満たします。
- 共有変数へのアクセスを排他制御する。
- 競合条件が発生しないようにする。
- データ構造の整合性を保つようにする。
スレッドセーフなクラスを使用することで、マルチスレッド環境におけるデータ競合を防ぎ、プログラムの信頼性を向上させることができます。
例えばArrayListはスレッドセーフでないクラスで、読み込み中に要素数が変動すると例外が発生します(java.util.ConcurrentModificationException)。
スレッドセーフなクラスの例:
- ConcurrentHashMap
- CopyOnWriteArrayList
- AtomicInteger
複数メソッドにまたがる排他制御(ReentrantLock)
synchronizedやatomicは単一のメソッドやフィールドに対して排他制御を実施できますが、複数メソッドにまたがる排他制御は実現できません。
そこで活躍するのがjava.util.concurrent.locks.ReentrantLockです。
「Re-Entrant(再び入る) をLockする」クラスで、一度lockメソッドが呼ばれるとunlockメソッドが呼ばれるまで別メソッドがlockメソッドを呼び出すことができません。
イメージとしては、1人(1スレッド)しか入れない部屋(インスタンス)を作るイメージかなと思います。
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.locks.ReentrantLock;
public class Main{
private static ReentrantLock mainLock = new ReentrantLock();
public static void main(String[] args) throws Exception {
ExecutorService exec = Executors.newFixedThreadPool(3);
for(int i=0;i<3;i++){
exec.submit(()->run());
Thread.sleep(10);
}
}
private static void run(){
try{
System.out.println(Thread.currentThread().getName() + " : Start");
mainLock.lock();
Thread.sleep(50);
System.out.println(Thread.currentThread().getName() + " : Lock");
Thread.sleep(100);
System.out.println(Thread.currentThread().getName() + " : UnLock");
mainLock.unlock();
}catch(InterruptedException e){
}
}
}
// 出力. unlockが呼ばれるまで次のlockが実行されない
// pool-1-thread-1 : Start
// pool-1-thread-2 : Start
// pool-1-thread-3 : Start
// pool-1-thread-1 : Lock
// pool-1-thread-1 : UnLock
// pool-1-thread-2 : Lock
// pool-1-thread-2 : UnLock
// pool-1-thread-3 : Lock
// pool-1-thread-3 : UnLock
ストリームAPI
Optionalクラス
Javaでは「返却された値がnullなら処理Aを、nullでないなら処理Bを行う」ということが頻繁にあります。(いわゆるnullチェック)
Optionalクラスは値をラップするクラスで、返却値がnullや異常値の場合の処理を簡略化することができます。
NullPointerExceptionは抑制できますが、結局何かしらのチェックは必要なので個人的にはあえて別クラスを持ち出すほどの意義は感じません。しかし、便利なメソッドは多いです!
Optionalインスタンスの作成(ファクトリメソッド)
Opotinalはコンストラクタが公開されていないので直接生成(new)できません。
次のファクトリメソッドを使用します。
- Optional.empty()
空のOptionalインスタンスを生成 - Optional.of()
null以外の値を持ったOptionalインスタンスを生成 - Optional.ofNullable()
null以外→値を持ったOptionalインスタンスを生成
null →からのOptionalインスタンスを生成
of()メソッドにnullを渡すと実行時に例外(NullPointerException)が発生します。
Optionalインスタンスの値の取得
Optionalインスタンスから値を取得する場合は、get()メソッドを使用します。
// インスタンスの値を取得 optional.get();
しかし、空のOptionalにgetメソッドを使用した場合、NoSuchElementExceptionが発生します。
従って、事前に以下のようなメソッドを使用してemptyチェックを行います。
- isPresent()
Optionalが空で無いならtrue - isEmpty()
Optionalが空ならtrue
場合分け処理① 値を取得する
ここら辺のメソッドをうまく使うと、簡潔に記述できることも多そうです。
ここでいう「簡潔」はif分を多用してネストを深くせずに済みそう、という意図です。
あえてOptionalを有効に使用するのであれば活用すべきメソッドだと感じます。
空の場合に固定の値を返す:orElse()
Optionalインスタンスが空の場合、引数に入れた値を返します。
optional.orElse("からの場合に返す値");
空の場合に特定の処理結果の値を返す:orElseGet()
Supplier型の関数を受け取ってその結果を返します。
orElseGetのgetはSupplierのメソッド名とそろえているんでしょう。
optional.orElseGet(()->{
return "明日は" + "晴れです。";
});
空の場合に例外を発生させる:orElseThrow()
Supplier型の関数を受け取ってそこで任意の例外をreturnします。
get()メソッドで発生するNoSuchElementExceptionは非検査例外であるため、検査例外を発生させ例外を出すことを明示的に表現する際などに利用可能です。
optional.orElseThrow(()->{
return new Exception();
});
場合分け処理② 値を受け取って処理する
空じゃない場合に処理を実行する:ifPresent()
Consumer型の関数を受け取って、Optionalが空じゃない場合に処理を実行します。
Optional<String> optional = Optional.of("sample");
optional.ifPresent((str)->{
System.out.println(str);
});
空じゃない場合と空の場合で別々の処理を実行する:ifPresentOrElse()
Consumer型の関数とRunnable型の関数を受け取って、Optionalが空じゃない場合は前者(Consumer)の処理を、空の場合は後者(Runnable)の処理を実行します。
Optional<String> optional = Optional.of("sample");
optional.ifPresentOrElse(
(str)->{System.out.println(str);}, // 空じゃない場合の処理
()->{System.out.println("empty!!");} // 空の場合の処理
);
場合分け処理③ 値を処理して新しいをOptionalを作成する
Optionalの値を処理して、結果をOptionalでラップして返す:map()
Function型の関数を受け取って、Optionalが空じゃない場合は処理結果の値をもった新しいOptionalインスタンスを返します。
- メソッドを使用するOptionalインスタンスが空の場合は空のOptinalを返す
- mapメソッドの処理がnullを返した場合空のOptionalを返す
実質的にnullチェックを内容しているので、使い勝手がよさそうです。
Optional<String> optional = Optional.of("sample");
// 出力:Optional.empty
// emptyの場合処理自体がスキップされるので、ラムダ式の結果にかかわらずemptyが返ります。
System.out.println(Optional.empty().map(str->"TEST"));
// 出力:Optional.empty
// nullを返すとemptyが返ります。
System.out.println(optional.map(str->null));
// 出力:Optional[SAMPLE]
System.out.println(optional.map(str->{
return str.toUpperCase(); // 大文字に変換
}));
Optionalの値を処理して、結果をOptionalで返す:flatMap()
Function型の関数を受け取って、Optionalが空じゃない場合は処理結果の値をもった新しいOptionalインスタンスを返します。
mapメソッドとの違いは、mapと異なり処理結果を自動的にOptionalでラップしないので、処理内でOptionalを作成して返す必要があることです。
Optional<String> optional = Optional.of("sample");
// 出力:Optional.empty
// emptyの場合処理自体がスキップされるので、ラムダ式の結果にかかわらずemptyが返ります。
System.out.println(Optional.empty().flatMap(str->Optional.of("TEST")));
// NullPointerException. flatMpではnullはretrunできない
// System.out.println(optional.flatMap(str->null));
// 出力:Optional[SAMPLE]
System.out.println(optional.flatMap(str->{
return Optional.of(str.toUpperCase()); // 大文字に変換
}));
ストリームAPI
コレクションの各要素に対して処理を記述する方法です。
メリットは次のようなところかなと思います。
- 豊富な中間処理(フィルタリングなど)と終端処理(条件一致や統計値の取得など)のメソッドを使用することができる。
- チェーンメソッドでつなげることができるので、処理の見通しがたちやすいかもしれない。
逆にfor文と比較した際のデメリットもあり、
- ラムダ式で処理を記述するため、実質的にfinalなローカル変数しか扱えない。
- break, continue, return, 例外のthrowができない
→処理の流れの制御ができない。
つまるところfor文と用途は似ていますが上位互換ではなくケースバイケースです。
ストリームの作成方法
配列からストリームを作成する
Arraysのstream()メソッドを使用して引数に配列を入れます。
String[] array = {"a", "b", "c"};
Stream<String> stream = Arrays.stream(array);
プリミティブ型のストリームを作成する場合は、Stream<int>のようにジェネリクス指定できないので専用の型を返すことが注意点です。
(String<Integer>のようにボクシングされません)
次のような専用の型があります。
- int配列:IntStream
- long配列:LongStream
- double配列:DoubleStream
FloatStreamなどは用意されておらず、DoubleStreamになるみたいです。
Collectionからストリームを作成する
java.util.Collectionインターフェースのstreamメソッドを使用します。
List<Integer> list = List.of(1,2,3); Stream<Integer> stream = list.stream();
ストリームの特徴
処理順序
ストリームの処理順序はコレクションが保持している順序です。
例
- ArrayList:要素を追加した順
- HashSet:ハッシュコード順
並列処理
ストリームはマルチスレッドをサポートしており、処理を並行して実行することができます。
ストリーム作成時にparallelStreamメソッドを使用すれば並行処理を実行できるStreamを作成できます。。
List<Integer> list = List.of(1,2,3); Stream<Integer> stream = list.parallelStream();
ただし、処理順は保証されなくなることに注意です。
forEachメソッドの代わりにforEachOrderedメソッドを使えば並行処理でも処理順を保証できますが、パフォーマンス向上のメリットが失われるのでいまいちですね。
ストリームの処理操作
処理の操作をまとめました。
試験で出てくるものは大体抑えられていると思います。
終端操作は一度し呼び出せません。2回呼び出そうとすると実行時に例外が発生します。
中間操作
| メソッド名 | 説明 |
|---|---|
filter | 条件を満たす要素のみを含むストリームを返す。 |
map | ストリームの各要素に対して関数を適用し、結果の新しいストリームを返す。 |
flatMap | 各要素に関数を適用し、結果として得られるストリームをフラット化して結合する。 |
distinct | ストリーム内の重複する要素を除外し、ユニークな要素のみを含むストリームを返す。 |
sorted | 自然順序や指定されたComparatorに従って、要素をソートしたストリームを返す。 |
peek | ストリームの各要素に対して操作を実行し、元のストリームを返す。 |
limit | ストリームの最初のn要素を含むストリームを返す。 |
skip | ストリームの最初のn要素をスキップし、残りの要素を含むストリームを返す。 |
終端操作
| メソッド名 | 説明 |
|---|---|
forEach | ストリームの各要素に対して指定された操作を実行。 |
toArray | ストリームの要素を配列に変換。 |
reduce | 累積的にストリームの要素を1つの値に集約。 |
collect | ストリームの要素をもとに新しいCollectionを返す。 |
min | ストリームの要素の最小値をOptionalで返す。(Comparatorを引数に渡す) |
max | ストリームの要素の最大値をOptionalで返す。(Comparatorを引数に渡す) |
count | ストリームの要素の数を返す。 |
anyMatch | ストリームの任意の要素が条件を満たすかを確認し、結果をbooleanで返す。 |
allMatch | ストリームの全要素が条件を満たすかを確認し、結果をbooleanで返す。 |
noneMatch | ストリームの全要素が条件を満たさないかを確認し、結果をbooleanで返す。 |
findFirst | ストリームの最初の要素をOptionalで返す。 |
findAny | ストリームの任意の要素をOptionalで返す。(基本的にはfindFirstと同じく最初の要素を返すが、並列処理の場合はどの要素が返るか不定。) |
Collecterインターフェース
ストリームを使っていろいろできます(雑)
一旦試験対策としては(そして、おそらく多くの実用上の場合も)Collecerインターフェースの実現クラスを自分で作成することはなく、Collectorsクラスのメソッドによる作成方法を把握しておけば問題ないと思います。
個人的にはgroupingByが頻出の割には複雑なので鬼門です。
余裕があるなら、オーバーロード含め押さえておくとよいと思いいます。
| メソッド名 | 説明 | 使用例 |
|---|---|---|
toList() | 要素をリスト (List) に収集します。 | List<String> result = stream.collect(Collectors.toList()); |
toSet() | 要素をセット (Set) に収集します。 | Set<String> result = stream.collect(Collectors.toSet()); |
toMap(keyMapper, valueMapper) | ストリームの要素をキーと値に変換してマップ (Map) に収集します。 | Map<String, Integer> result = stream.collect(Collectors.toMap(String::valueOf, String::length)); |
joining() | 文字列のストリームを単一の文字列に結合します。デフォルトでは区切り文字はありません。 | String result = stream.collect(Collectors.joining()); |
joining(delimiter) | 指定された区切り文字で文字列のストリームを結合します。 | String result = stream.collect(Collectors.joining(", ")); |
counting() | ストリーム内の要素数をカウントします。 | Long count = stream.collect(Collectors.counting()); |
summingInt(mapper) | ストリーム内の要素を整数に変換し、その合計を計算します。 他に、「summingLong」「summingDouble」もあります。 | int sum = stream.collect(Collectors.summingInt(String::length)); |
groupingBy(classifier) | 要素を分類関数 (classifier) に基づいてグループ化し、マップに収集します。 | Map<Integer, List<String>> result = stream.collect(Collectors.groupingBy(String::length)); |
partitioningBy(predicate) | 条件を満たすかどうかに基づいて、要素を2つのグループ(true と false)に分割します。つまり、trueとfalseをキーとしたMapが作成されます。 | Map<Boolean, List<String>> result = stream.collect(Collectors.partitioningBy(s -> s.length() > 3)); |
reducing(identity, accumulator) | ストリームの要素を1つの値に畳み込む(リダクション)操作を行います。初期値と結合関数を指定します。 | Integer sum = stream.collect(Collectors.reducing(0, String::length, Integer::sum)); |
おまけ
forEach
forEachメソッドはstream APIでなくてもコレクションにも定義されているので、簡単な操作ならストリームにする必要がありません。
forEachメソッドは、コレクションの各要素に対して指定された処理を順番に実行するためのメソッドです。
処理はConsumer型で指定します。
import java.util.Arrays;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = Arrays.asList("apple", "banana", "cherry");
list.forEach(item -> System.out.println(item));
}
}
// 出力
// apple
// banana
// cherry
この分量でようやく黒本の半分くらいです(白目)
ただ、あくまで「ページ数でいえば半分くらい」というだけで、出題数でいえばこの記事で7割くらいはカバーできているんじゃないかと思います。
それほどまでにストリームAPIが頻出でした。
